Social Comet ISON Statistics
Posted on Mon 02 December 2013 in comets
Users of Twitter posted up to 12,000 messages per hour during Comet ISON's perilous encounter with the Sun last Friday. Events like this provide us with an opportunity to understand the demographics of the audience exposed to astronomy through social media.
Using the public API provided by Twitter, I was able to automatically collect the thousands of comet-related messages by querying for tweets containing the keyword "ISON". During the ten-day period between November 20 and 30, I harvested 331,952 tweets about the doomed little planet in this way. The messages originated from no less than 141,899 unique Twitter accounts.
The social activity peaked in the evening of November 29th, which is when the ill-fated object was prematurely pronounced dead on Twitter by several high-profile accounts such as NASA, ESA and BBC. At that time, the activity jumped to 3 tweets per second (tps) for several hours, which is impressive if you consider that Michael Jackson's death in 2009 peaked only 150 times higher at 456 tps. Reports of ISON's death were greatly exaggerated however, whilst Jackson's wasn't.
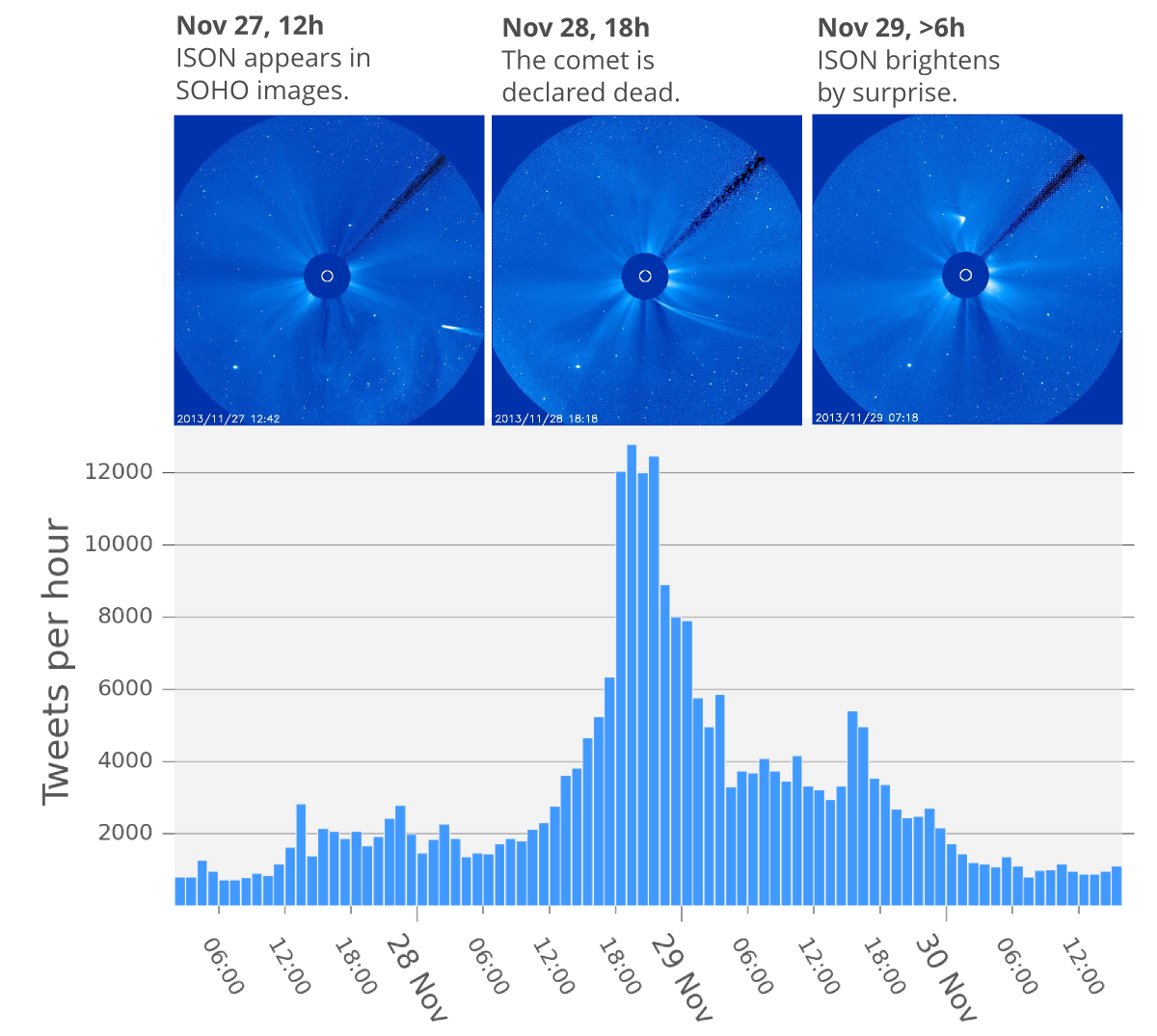
Number of tweets containing the word ISON during the Comet's close encounter with the Sun. All times are in Universal Time (UT).
A reason for collecting social data like these is that they may inform us about the demographics of the audience reached through social media. Indeed, in addition to the messages themselves, the Twitter API offers indirect information on the user's profile such as their location, their followers and past tweets. Understanding the audience is useful because astronomical outreach is often hampered by the problem of preaching to the converted, that is, many activities tend to reach people who were already astronomy fans at the outset. It is possible that outreach carried out through social media is less affected by this problem, but it is not obvious and could be tested. (Also see my previous post on using YouTube analytics for this purpose.)
Having said all that, I haven't actually tried to infer any demographics from these data at present. Doing so would involve building a probabilistic model to infer e.g. gender and ethnicity (from the profile picture) and affinity with science (from past tweets). This requires algorithms which are more likely to be found in the marketing departments of large corporations rather than on code-sharing sites like GitHub, and hence the task is not trivial.
Anyone interested in this data science challenge?